

Data Science Studiengang bei Konferenz in Rom vertreten
Zwei Studentinnen aus Wirtschaftsinformatik - Data Science stellen auf der 15th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management in Rom ihre Scientific Paper zu den Themen "Speech Detection of Real-time MRI Vocal Tract Data" und "Detecting Greenwashing in the Environmental, Social, and Governance Domains Using Natural Language Processing" vor.


Greenwashing Paper:
Vorneweg: Greenwashing bedeutet die irreführende Darstellung von Umwelt-, Sozial- und Governance-Werten (ESG) durch Unternehmen.
Diese Studie untersuchte den Zusammenhang zwischen der Einschätzung, wie die ESG-Werte von Unternehmen (12 Pharmaunternehmen von 2012 bis 2022) dargestellt werden ("interne Sentimente") und der öffentlichen Meinung , die insbesondere über sozialen Medien geäußert werden ("externe Sentimente"). Mithilfe von natürlicher Sprachverarbeitung (NLP) werden offizielle Dokumente der Unternehmen (wie Geschäftsberichte, Ad hoc-Meldungen) und Äußerungen über soziale Medien analysiert. Die Ergebnisse zeigen keine signifikante Korrelation zwischen den beiden Quellen der Stimmungen, was auf potenzielles Greenwashing hinweist. Greenwashing kann für Stakeholder (wie Investoren und Aufsichtsbehörden) ein Alarmsignal sein. Als Antwort darauf wird ein NLP-basiertes Q&A-System vorgeschlagen, das kontextspezifische Fragen zur ESG-Bilanz eines Unternehmens generiert und damit eine mögliche Lösung zur Erkennung von Greenwashing bietet.
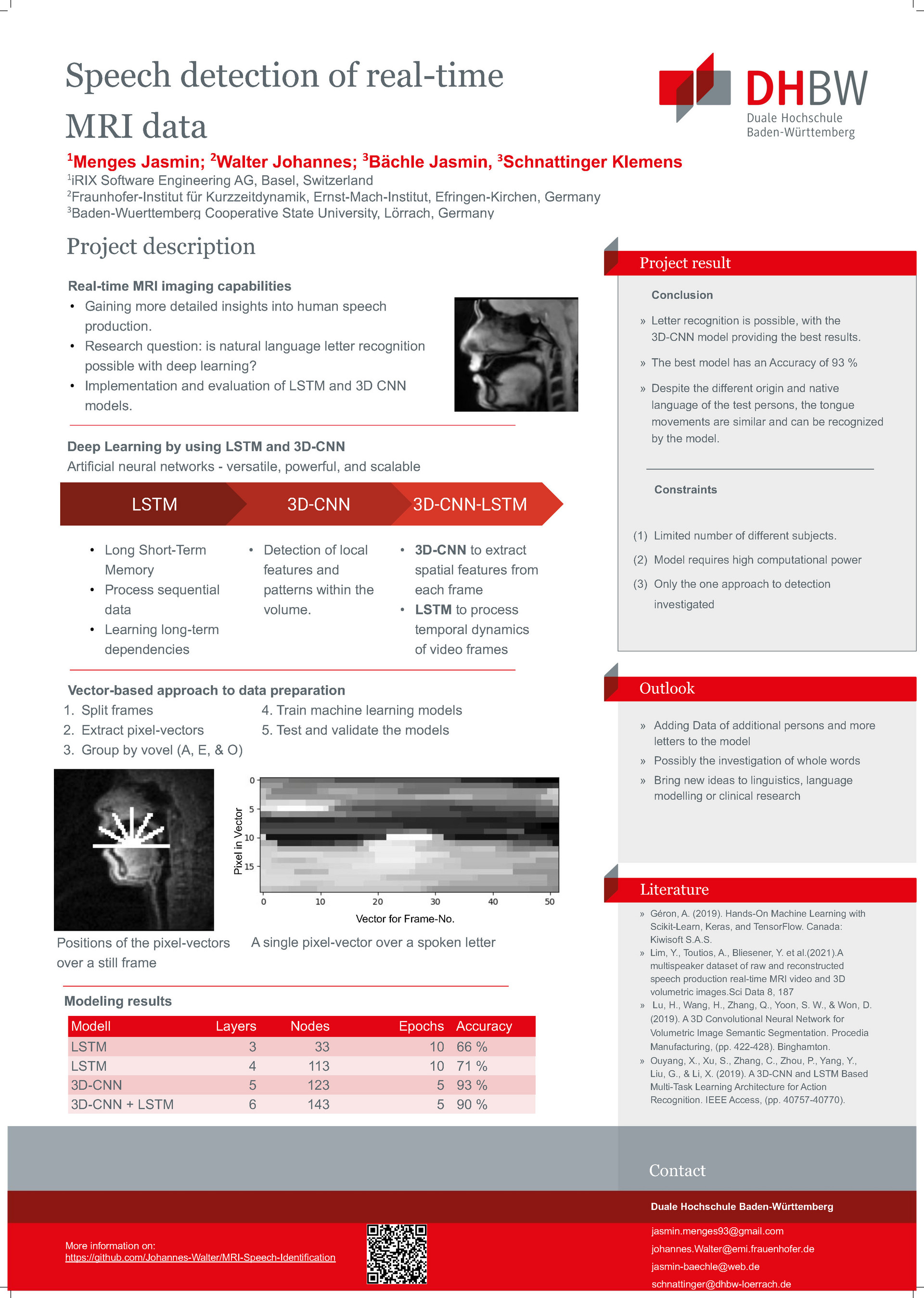
MRI Paper:
In diesem Beitrag wird das Potenzial von Deep Learning im Bereich der Sprachproduktion untersucht, konkret wird untersucht, ob eine KI in der Lage ist, den gesprochenen Inhalt nur auf der Grundlage von Bildern der Mundregion zu klassifizieren. Mit den Echtzeit-MRT-Daten von Lim et al. konnten detailliertere Erkenntnisse über die Sprachproduktion des Stimmapparates von Menschen gewonnen werden. Dazu wurden die Daten zur Erkennung gesprochener Buchstaben anhand von Zungenbewegungen mit Hilfe eines vektorbasierten Bilderkennungsansatzes verwendet. Um mehr Daten zu generieren, wurde zusätzlich eine Randomisierung durchgeführt. Die Pixelvektoren eines Videoclips, in dem ein bestimmter Buchstabe gesprochen wurde, konnten dann an ein Deep Learning-Modell übergeben werden. Zu diesem Zweck wurden die neuronalen Netzwerke LSTM und 3D-CNN verwendet. Es konnte nachgewiesen werden, dass mit einem 3D-CNN-Modell Buchstaben mit einer Genauigkeit von 93% klassifiziert werden können.